Intro to Julia: The Future of Data Science
The never-ending debate of what programming language to use for data science rages on, one to which I myself have contributed in my own, small way. The most recent contender to the battle, an unexpected third party sneaking in between the juggernauts of Python and R, is a relatively new language called Julia.
You may have heard of Julia before. Many people have declared it to be, as I have in the title, the future of data science. Medium is full of blog posts about how Julia is the next best thing, Julia is Python's replacement, and what challenges Julia has on its way to global supremacy.
But what is Julia? What does it do, what is it for? What does it look like? Why did somebody make a new programming language in an age of endless language choices?
That's what I'm here to discuss today. You can find an interactive notebook version of this blog post on my Deepnote profile. Stay tuned for my true thoughts on Julia at the end.
What is Julia?
Julia, released in 2012, was primarily created to solve the "two language problem" in scientific computing. While most scientific problems require the speed and power of lower level languages like C and Fortran, these languages are difficult to write in and don't lend themselve to fast development time. Higher level languages, particularly Python, allow for rapid writing and testing of code, but don't have the speed required for efficient calculations.
This has led to scientists and data scientists developing a workflow that sees them developing solutions in Python on test or toy data sets, then rewriting their solutions in a lower-level language before actually performing the computation.
Julia was created primarily to solve this problem and allow programmers in these fields the ability to develop and prototype in the same langauge that they use in the final product, decreasing time to production and the many headaches that come from translating code from one language to another. Julia's creators were also "greedy" (their words, not mine) and sought to create a language that had all of their favorite features in a single language. To quote them:
“We want a language that’s open source, with a liberal license. We want the speed of C with the dynamism of Ruby. We want a language that’s homoiconic, with true macros like Lisp, but with obvious, familiar mathematical notation like Matlab. We want something as usable for general programming as Python, as easy for statistics as R, as natural for string processing as Perl, as powerful for linear algebra as Matlab, as good at gluing programs together as the shell. Something that is dirt simple to learn, yet keeps the most serious hackers happy. We want it interactive and we want it compiled.
(Did we mention it should be as fast as C?)”
The result is a language that looks and writes like Python but runs almost as fast as C, with the flexibility of modern Lisps. While the community is small and is a lot less mature than Python's or R's, it has been growing rapidly and has become a serious contender in the data science and scientific computing space. At the time of writing, Julia stands at #36 of TIOBE's index, just below Scala, another popular data science language.
In 2017, Julia joined the elite club of programming languages, the Petaflops Family. Along with C, C++, and Fortran, Julia has been able to perform (on a supercomputer with 1.3 million threads) over 10e15 floating point operations per second. Applied in the Celeste project, dedicated to cataloguing all of the telescope data for the stars and galaxies our visible universe, Julia code was able to achieve ~1.54 PF/s.
What does Julia look like?
Fortran and C/C++ are very powerful languages and are the go-to for most programmers seeking performance in large-scale operations, but they are far from user-friendly. Code written in these languages, especially when optimized for high performance, tends to be dense and hard to untangle. The main benefit of Julia is that we can achieve the same or similar performance as these languages while having the readability of Python code.
So what does it look like?

Monte Carlo method for estimating Pi, using Julia
The above code is a function that I stole from the numba website. Its function is to estimate the value of pi by generating a random points and checking to see if they fall within a circle. The numba website uses it to demonstrate the power of their just-in-time (JIT) compiler for Python, but it also does well to demonstrate the power of Julia's JIT compilation and its interpretability.
If you're familiar with Python, you'll find Julia is very similar; there are a few differences here and there, but the syntax is essentially the same. Typing can be enforced (nsamples::Int64) and creating lazy sequences is extremely simple (0:nsamples). One must use the keyword end after loops, conditionals, and functions instead of just returning to the original indent level, but other than these differences, the code for Python and Julia are almost interchangeable. This is a great boon for developers like me who are extremely used to Python by now. You can check the numba site linked above if you would like to compare them yourself.
You can see that I ran this estimation in Julia 100 million times and the function estimated pi to 4 decimals within about a half a second. For reference, when I ran the same code in Python (without numba), the process took around 17 seconds, meaning that switching to Julia for this problem provided a significant speed-up. Using numba, Julia still beat out Python by a few hundreths of a second.

Data. Idk, I just wanted to break up the article a little bit.
Features of Julia
Now that we've gotten a taste of what Julia looks like, what are some cool features that it brings to the table and make it worth learning?
The REPL
REPL stands for Read Evaluate Print Loop and is a way for programmers to interactively code in their terminal without having to worry about creating or running an entire file. If you're familiar with Python, Clojure, Scala, or some other languages, you're probably already familiar with the REPL. Julia's REPL is one of my favorites, as it encorporates some new features:
ans: Ever wanted to just use the result of the last computation for your new line of code? Julia's REPL gives you theanskeyword, which is whatever your last line of code returned- block history: Often in Python, I'll make a mistake and have to pound my up-arrow in order to rerun all of the correct lines from my code block. In Julia, a function, loop, or conditional block is one whole piece, and you can scroll back in your history and directly edit the block by itself
built-in package manager: No more having to stop your Python REPL in order to install the package you want, with Julia you can just hit
]and enter to the package manager. Then when you're done, you can just hit yourbackspaceto get back to work.Each of these features are demonstrated below:

Short gif of me adding a fake package, then going right back to the REPL
Mathematical Notation
Because Julia was made to cater to scientific pursuits, you're able to use a variety of symbols in your code in order to bridge the gap between your equations and the functions you're writing.

Example of some of the many unicode characters you can use in your code
This means that if you're dealing with, say, physics equations, you can use the actual symbols you'd use on paper within the code, and still assign values to them as variables. Any editor supporting Julia (including the REPL) should allow you to do this by typing in a backslash (\) and then the symbol name (ex: \Delta in the first example) and hitting the Tab key.
Exploding Arguments
To either explode an iterable variable into its pieces or allow a function to take an indeterminate amount of arguments, in Python we would use the asterisk (*) symbol. In Julia, we can do the same with ...

Having the ability to explode variables in such a way is useful for writing functions that may have a varying number of arguments. This feature isn't unique to Julia, but it's good to know that it's a feature that is included in the language.
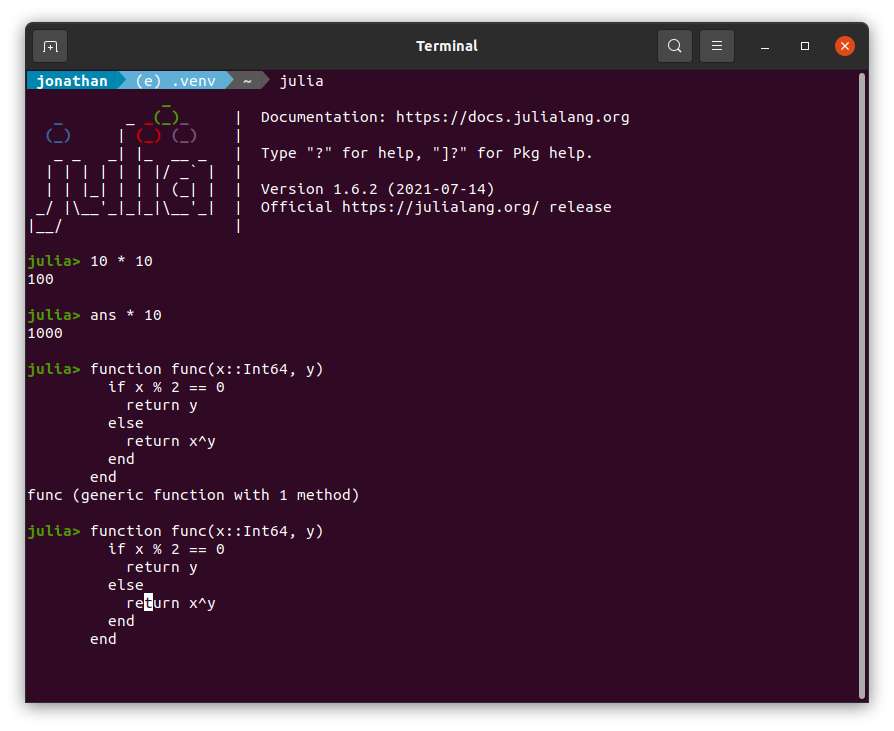
Optional Typing
Typing is optional in Julia. There may be a reason that you want to enforce types, or there may be a reason that you don't. Julia doesn't care either way. Whichever types you want enforced, it'll enforce, and it won't enforce the ones you don't. Often, enforcing typing helps with execution speed, but if you're just whipping up a prototype and don't want to worry about the specifics of typing, it's not a requirement.
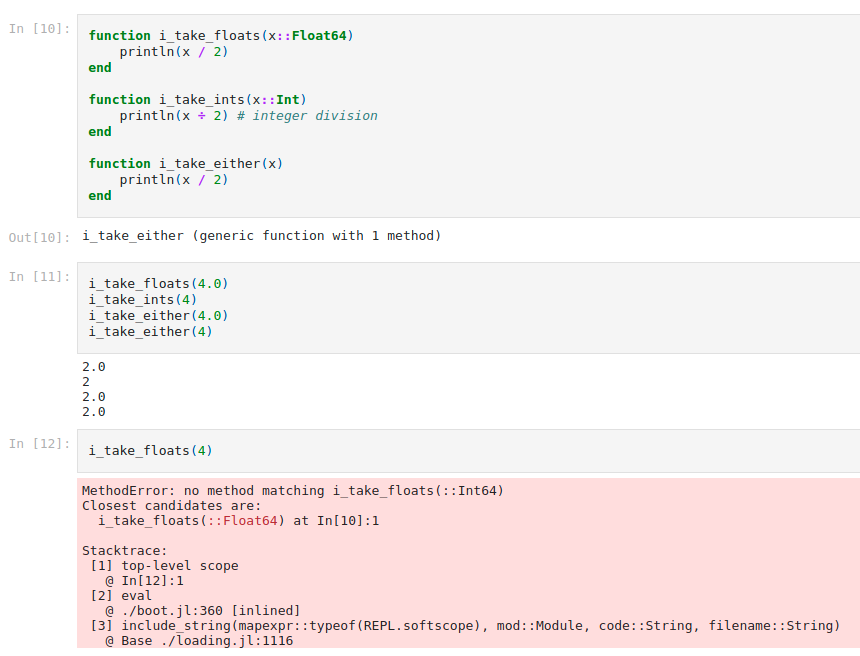
Typed and untyped functions
Interop
Interoperability, or "interop," is Julia's ability to call on the strength of other programs to leverage their features. Using interop, we can call Python libraries like Pandas and Numpy or call functions from C++ or Fortran for an extra speed boost. This means that Julia can fit more easily into an existing workflow, and any weaknesses that Julia may have for your usecase might be able to be shored up by these other languages.
Below, we'll call a popular Python visualization library, matplotlib, into Julia and use its API in the same way we'd use it in Python.

Import matplotlib.pyplot as plt, as usual, then graph a curve
Multiprocessing, Multithreading, and Asynchronous
These features allow for multiple operations to take place at the same time. We saw an example of Julia's multithreading power over the 1.3 million threads of the Celeste project. The same speeds can be applied to multiple machines in cluster computing situations. Asynchronous programming also allows for detailed coordination of tasks within a program for optimal speed. While I don't have much experience with using these in the context of Julia, the tools are meant to be straightforward and easy to drop-in.
The below code will run our Monte Carlo Pi estimation function from earlier, with n number of iterations, with n being every step of 1,000 from 1,000 to 1 million. Each of these jobs can be distributed among the cores being used, meaning that instead of doing each simulation one at a time, several can be done simultaneously.

Multiple Dispatch
Saving the best for last, Julia's multiple dispatch feature is my personal favorite. Multiple dispatch refers to the way that Julia references functions; while Python might see only the function's name, Julia also sees the type of its arguments. This allows us to write multiple functions with the same name that take different types or numbers of variables.
In our previous example about typing, we had three different functions that performed the same operation but only accepted certain data types. With multiple dispatch, we can write several functions with the same name where each addresses those variable types, sort of like an in-built switch statement.
Below, I've written three different dummy functions, building on each until I have a function that accepts two integers, one string and one integer, or two strings, and treats them all very differently.
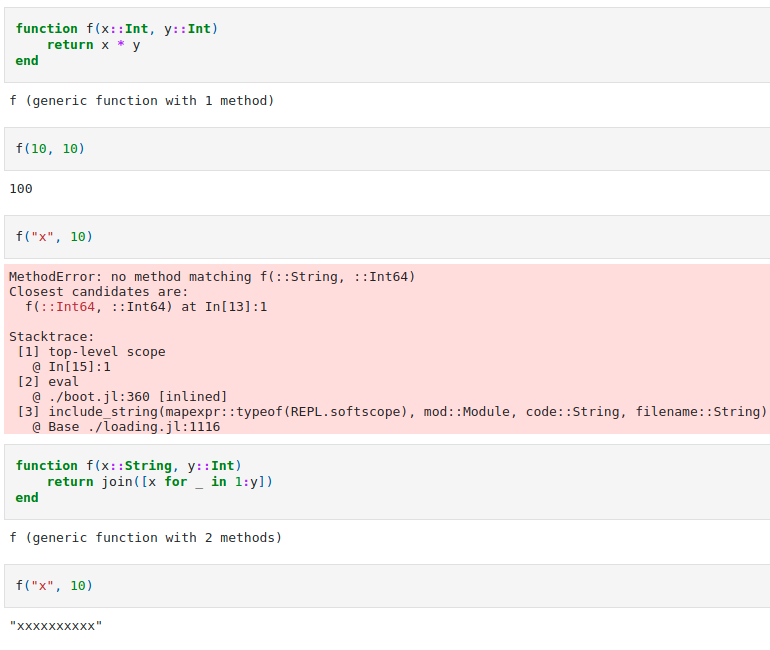

Is Julia ready for the big time?
Not quite. Julia is a very new language (Python has been in development since 1991 vs Julia since 2009) and doesn't have a lot of widespread adoption. Its data science tools are still coming into their own, and while there are a lot of promises of high performance, the benefits don't necessarily outweight the costs of adopting a smaller, less established language.
Although all of the above is true, Julia is still considered by many, including myself, to be the future of data science and scientific computing, and its presence should not be taken lightly. The adoption curve for Julia is much faster than Python's, and it's been making huge jumps in popularity over the past couple of years. It wouldn't be too crazy to say that Julia may have a large part in our data science lives in the coming years.
Experimentation with new technologies is important in our industry, and while Julia may not yet be the first choice of many data scientists, I expect it to be in the near future. It's hard to let go of a language that you're familiar with in favor of one that, while similar, is still very different, even if the new language solves a lot of your problems.
I feel that as the community grows and the language and its tools mature, Julia will be the lingua franca of data scientists of the future.
Better get a head start.